Zadanie
Anotácia
Táto bakalárska práca sa zameriava na adaptáciu metriky h-index pre prostredie GitHub s cieľom kvantifikovať „vplyv" vývojára alebo repozitára na základe popularity a využívania jeho projektov. V práci navrhujem definíciu GitHub h-indexu odvodenú z počtu citácií na GitHube (napr. hviezdičky, forky a ďalšie signály), analyzujem dostupnosť a obmedzenia dát z GitHub API a popisujem postup zberu a spracovania údajov. Súčasťou je implementácia prototypu, ktorý vypočíta metriky pre zvolených používateľov a repozitáre, a porovnanie výsledkov s tradičnými indikátormi aktivity. Výsledkom je návrh metriky a webová prezentácia, ktorá umožňuje prehľadne zobraziť vypočítané hodnoty a diskutovať ich interpretáciu a limity.
Cieľ
Cieľom bakalárskej práce je adaptovať bibliometrickú metriky h-index na prostredie GitHub a navrhnúť spôsob, ako pomocou verejne dostupných údajov spoľahlivo kvantifikovať „vplyv" používateľov a repozitárov. Práca sa zameriava na definovanie GitHub h-indexu na základe merateľných signálov (napr. hviezdičky a forky), na návrh metodiky zberu a spracovania dát s ohľadom na obmedzenia GitHub REST/GraphQL API a na implementáciu prototypu, ktorý tieto metriky vypočíta a umožní ich porovnávanie a interpretáciu.
Vizualizácie
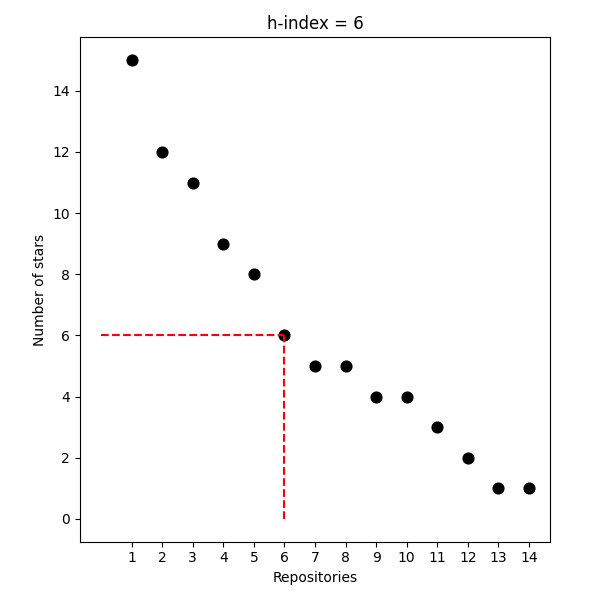
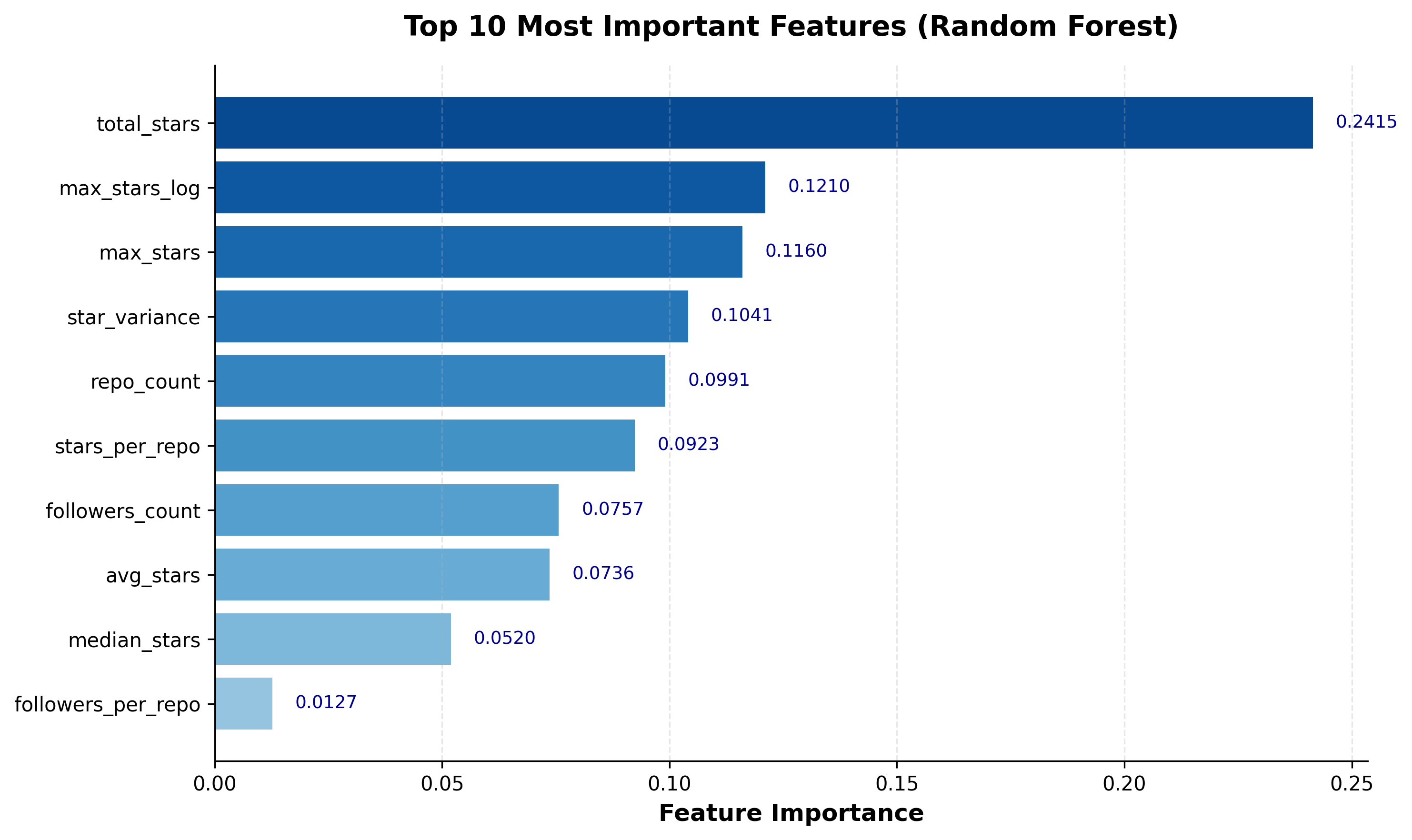
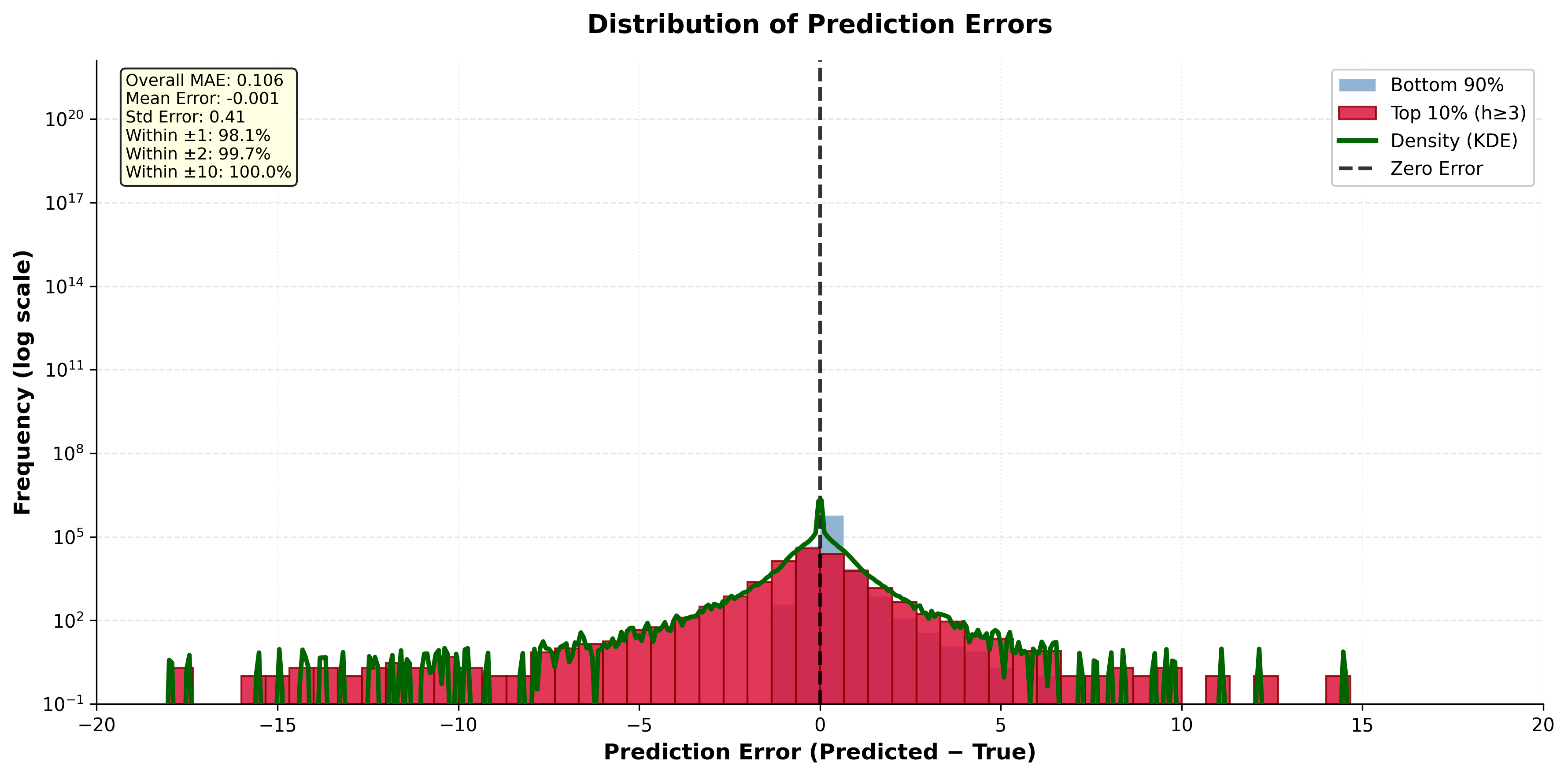
Nasledujúce grafy ilustrujú kľúčové aspekty navrhovanej GitHub h-index metriky:
Prezentácia
Stiahnite si prezentáciu bakalárskej práce v preferovanom formáte:
Zdroje a odkazy
-
Zobraziť literatúru
Zoznam použitej literatúry
- HIRSCH, Jorge E., 2005. An index to quantify an individual's scientific research output. Proceedings of the National Academy of Sciences, vol. 102, no. 46, pp. 16569–16572. Dostupné na: https://doi.org/10.1073/pnas.0507655102
- LARSEN, R. L., 2007. The future of scholarly communication: Building the infrastructure for cyberscholarship. Journal of the American Society for Information Science and Technology, roč. 58, č. 7, s. 1061–1066. Dostupné na: https://asistdl.onlinelibrary.wiley.com/doi/full/10.1002/asi.20609
- ESCAMILLA, Emily; KLEIN, Martin; COOPER, Talya; RAMPIN, Vicky; WEIGLE, Michele C.; NELSON, Michael L., 2022. The Rise of GitHub in Scholarly Publications. In: Silvello, G.; Corcho, O.; Manghi, P.; Di Nunzio, G.M.; Golub, K.; Ferro, N.; Poggi, A. (eds.) Linking Theory and Practice of Digital Libraries. TPDL 2022. Lecture Notes in Computer Science, vol. 13541. Springer, Cham, pp. 187–200. Dostupné na: https://doi.org/10.1007/978-3-031-16802-4_15
- GILROY, Shawn P.; KAPLAN, Brent A., 2019. Furthering Open Science in Behavior Analysis: An Introduction and Tutorial for Using GitHub in Research. Perspectives on Behavior Science, vol. 42, pp. 565–581. Dostupné na: https://doi.org/10.1007/s40614-019-00202-5
- PERKEL, Jeffrey, 2016. Democratic databases: science on GitHub. Nature, vol. 538, pp. 127–128. Dostupné na: https://doi.org/10.1038/538127a
- BLINCOE, Kelly; SHEORAN, Jigyasa; GOGGINS, Sean; PETAKOVIC, Emil; DAMIAN, Daniela, 2016. Understanding the popular users: Following, affiliation influence and leadership on GitHub. Information and Software Technology, vol. 70, pp. 30–39. Dostupné na: https://doi.org/10.1016/j.infsof.2015.10.002
- GitHub, 2026. Rate limits for the REST API. GitHub Docs. Dostupné na: https://docs.github.com/en/rest/using-the-rest-api/rate-limits-for-the-rest-api
- GitHub, 2026. Rate limits and query limits for the GraphQL API. GitHub Docs. Dostupné na: https://docs.github.com/en/graphql/overview/rate-limits-and-query-limits-for-the-graphql-api
- BREIMAN, Leo, 2001. Random Forests. Statistics Department, University of California, Berkeley. Dostupné na: https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf
- scikit-learn developers, 2026. Effect of transforming the targets in regression model. scikit-learn Documentation. Dostupné na: https://scikit-learn.org/stable/auto_examples/compose/plot_transformed_target.html
- SPEARMAN, Charles, 1904. The Proof and Measurement of Association between Two Things. The American Journal of Psychology, vol. 15, no. 1, pp. 72–101. Dostupné na: https://doi.org/10.2307/1412159
- Aktuálna verzia bakalárskej práce: Otvoriť PDF
Denník
-
1. týždeň
- Oboznámil som sa so zadaním bakalárskej práce a definoval hlavné ciele projektu. Vykonal som rešerš literatúry zameranej na h-index metric (Hirsch, 2005), využitie GitHubu vo vedeckom výskume a existujúce metriky hodnotenia vplyvu vývojárov. Zhromaždil som kľúčové zdroje pre teoretickú časť práce.
- Naštudoval som si princíp h-indexu a jeho výpočet. Analyzoval som, ako by sa dala táto metrika adaptovať na prostredie GitHubu – repozitáre ako publikácie a hviezdičky ako citácie. Stanovil som výskumné otázky práce.
-
2. týždeň
- Vypracoval som detailnú definíciu GitHub h-indexu: hG = max {i ∈ {1,…,n} : si ≥ i}, kde používateľ má aspoň hG repozitárov, každý s aspoň hG hviezdičkami. Implementoval som algoritmus výpočtu v Pythone.
- Rozhodol som sa používať hviezdičky ako ekvivalent citácií (nie forky) – zdôvodnil som to analógiolu s akademickými citáciami. Analyzoval som limity metriky: hviezdičky ako záložky, možnosť kúpených hviezdičiek a problém údržby repozitárov.
-
3. týždeň
- Preskúmal som GitHub REST a GraphQL API, ich dokumentáciu a obmedzenia. REST API: 5 000 requestov za hodinu na autentifikovaného používateľa. GraphQL API: 5 000 bodov za hodinu s point-based systémom. Rozhodol som sa uprednostniť GraphQL API pre efektívnejší zber dát.
- Navrhol som architektúru aplikácie a systém multi-token rotation. Vytvoril som TokenManager triedu, ktorá distribuuje požiadavky cez viacero access tokenov, čo umožňuje zvýšiť rýchlosť zberu dát až 8-násobne.
-
4. týždeň
- Implementoval som zber používateľov z GitHubu. Riešil som API obmedzenie – maximálne 1 000 používateľov na jeden query. Použil som filtrovanie podľa počtu followerov a dátumu registrácie na segmentáciu priestoru používateľov.
- Vytvoril som checkpointing systém, ktorý ukladá stav spracovania a umožňuje obnovenie pri výpadku. Zber dát bežal približne týždeň a získal informácie o ~3,5 miliónoch používateľov.
-
5. týždeň
- Implementoval som zber repozitárov pre všetkých 3,5 milióna používateľov. Počiatočné sekvenčné spracovanie dosahovalo priepustnosť ~10 000 používateľov za deň, čo by trvalo ~350 dní.
- Zaviedol som paralelné spracovanie s token rotation – používatelia sa spracúvajú v dávkach po 5 paralelných vláknach. Monitorujem rate limit headers a pri vyčerpaní tokenov prepínam na dostupné. Tým sa rýchlosť zvýšila 8-násobne a zber všetkých repozitárov skončil za ~5 dní.
-
6. týždeň
-
Implementoval som modulárny parser pre JSON odpovede REST API. Extrahuje kľúčové polia:
stargazers_count,forks_count, dátum vytvorenia repozitára a informácie o prispievateľoch. - Vyriešil som spracovanie paginovaných odpovedí – postupné prechádzanie stránok výsledkov a ich zlučovanie. Ošetril som edge cases: chýbajúce polia, null hodnoty a neočakávané formáty. Vytvoril som validačnú vrstvu kontrolujúcu integritu dát.
-
Implementoval som modulárny parser pre JSON odpovede REST API. Extrahuje kľúčové polia:
-
7. týždeň
- Rozšíril som parser o spracovanie GraphQL odpovedí. Implementoval som extrakciu komplexných vnorených štruktúr – vzťahy medzi repozitármi, commitmi a pull requestmi. Tieto signály sú dôležité pre refinovanie metriky.
- Zameral som sa na normalizáciu dát: konverzia časových značiek na jednotný formát, štandardizácia identifikátorov a transformácia aktivít na číselné váhy. Implementoval som caching mechanizmus pre dáta a incrementálne parsovanie.
-
8. týždeň
-
Implementoval som obohatenie profilov – zber dodatočných metadat cez GraphQL API:
followers_count,following_count,organizations_count,bio,company,location. -
Vytvoril som pipeline na extrakciu a normalizáciu sociálnych odkazov (Twitter, LinkedIn, Instagram, YouTube, Telegram). Implementoval som prioritný systém priraďovania typov odkazom. Navrhol som SQLite databázu s tabuľkami
users,repositoriesauser_links.
-
Implementoval som obohatenie profilov – zber dodatočných metadat cez GraphQL API:
-
9. týždeň
- Vybral som Random Forest ako model pre predikciu h-indexu – ensemble metóda, ktorá je robustná voči outlierom a poskytuje feature importance. Rozhodol som sa trénovať dva modely: klasický a s log2 transformáciou cieľovej premennej.
-
Vytvoril som 13 featureov:
repo_count,total_stars,max_stars,star_variance,stars_per_repo,followers_count,following_count,followers_per_repo,following_to_followers,organizations_count,bio_length. Pripravil som dataset – 80/20 split s fixed seed.
-
10. týždeň
- Trénoval som oba Random Forest modely (~2,5 minúty každý). Klasický model dosiahol MAE 0,150 a R² 0,9241 celkovo; pre top 10% používateľov MAE 0,712. Log2 model dosiahol MAE 0,153 a R² 0,9142.
- Vykonal som chybovú analýzu – distribúcia rezíduí je symetrická, najväčšie chyby sú pri extrémnych h-index hodnotách (>30). Oba modely podhodnocujú špičkových používateľov. Vypracoval som case studies (Sindre Sorhus, Keijiro Takahashi, Phil Wang a ďalší).
-
11. týždeň
- Analyzoval som prítomnosť vývojárov na sociálnych sieťach. Twitter je najpopulárnejší (50,9 %), nasleduje LinkedIn. Zostavil som rebríček top 20 používateľov podľa GitHub h-indexu – víťazom je Sindre Sorhus s h-indexom 253.
-
Vykonal som Spearmanovu korelačnú analýzu GitHub metrík. Potvrdil som, že
total_starsje najdôležitejší feature. Zistil som slabú koreláciu medzi počtom followerov a h-indexom. Negatívna korelácia medzi počtom repozitárov a priemerným počtom hviezdičiek.
-
12. týždeň
- Dokončil som písanie bakalárskej práce – spracoval som všetky kapitoly, limitations a future work. Pripravil som prezentáciu vo formátoch PDF a PPTX.
- Finalizoval som webovú stránku – vizualizácie výsledkov, prehľadné zobrazenie metrík a denne aktualizované informácie o projekte. Zhodnotil som dosiahnuté výsledky a navrhol smery ďalšieho výskumu.