Processing of 3D Scans using Machine Learning
Overview
Supervisor: RNDr. Martin Madaras, PhD.
Neural networks have been found as very efficient machine learning tool for image processing tasks. During the 3D scanning depth maps are created. Having a known and calibrated camera, the depth maps can be converted into a structured point cloud. Structured point clouds are similar as standard frame, they are 2D matrices of points, where every sample carries the 3D position information. The structured point clouds have the same structure as the 2D image data, with the additional 3D position information, thus the neural networks designed for 2D image processing can be used for these 3D data.
The goal of the thesis is to analyze existing neural network models that are used in image processing or signal processing in general and to propose an effective modifications, how to use these approaches to point cloud processing. Compare proposed models with the existing ones and evaluate the results. Apply proposed models for 3D image processing tasks as filtering, segmentation etc. and use them in post-processing pipeline of 3D scanner data.
Links
PDF Text Work-In-Progress
Project Seminar (1) Presentation
Project Seminar (2) Presentation
Github Repository
Github Commits
Progress Presentations
Together with other students under the guidance of our common supervisor, we hold a seminar every other week, where we discuss our progress. As a part of these, I usually prepare a presentation with an overview of my updates.
(11.11.2020 - 23.11.2020)
(28.10.2020 - 10.11.2020)
(30.08.2020 - 13.09.2020)
(21.07.2020 - 01.08.2020)
(06.07.2020 - 20.07.2020)
(00.00.2019 - 00.00.2019)
Filtration Model
First version of the trained model for artefact cleaning was released on Github with all code and trained weights.
Alternatively, you can try experimental Google Colab release for remote execution.
HW Requirements: Nvidia CUDA accelerated GPU
SW Requirements: CUDA 10.1, cuDNN SDK 7.6, Python 3.7+, Tensorflow 2.0+, Keras 2.4.3+
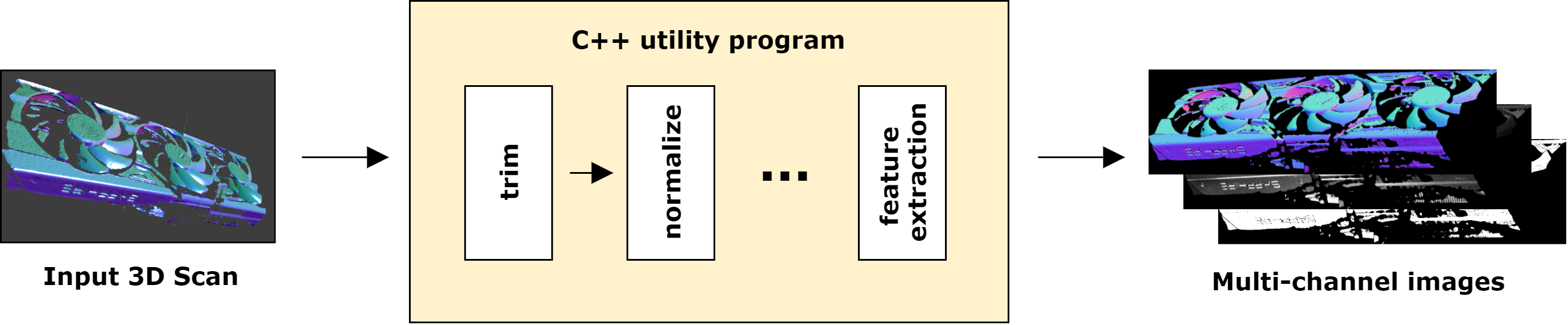
Converter Utility
A utility for processing scans obtained by structured light scanner was made. It is an console application, that accepts scans in the .cogs format and converts them into more general formats for ML training. Example of those are feature images, or .csv text files, for easy manipulation and import into Numpy arrays, further processed in libraries like Keras. The utility was released publicly for usage by other students and researchers.
Filtration Animations
Results







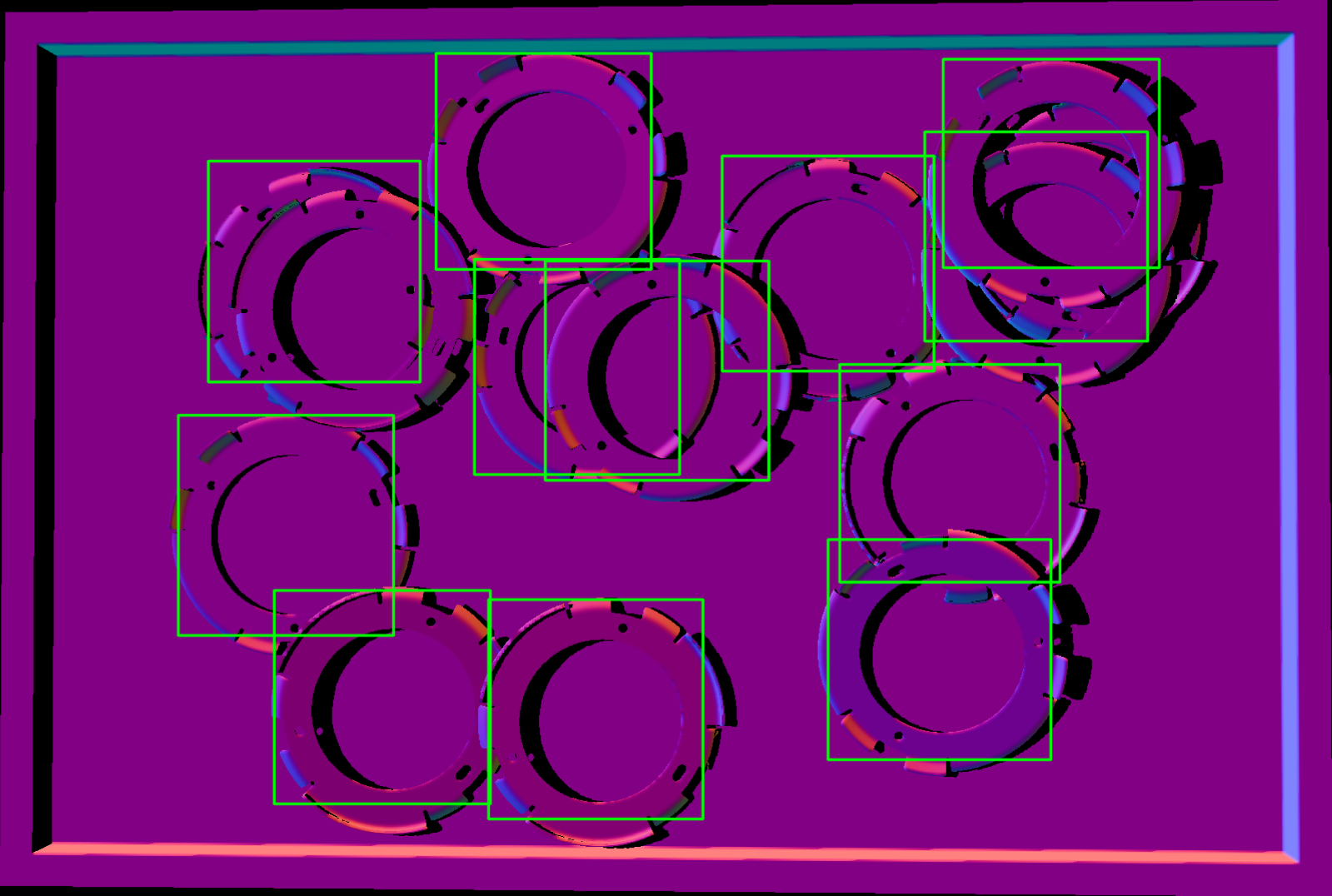
ML Course Project
The following documents, presentations and implementations have been made as the semestral project for the Machine Learning course at FMFI UK and other activities:
Sources
| [1] | R. Charles, Hao Su, Mo Kaichun, and Leonidas Guibas. PointNet: deep learning on point sets for 3D classification and segmentation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 77--85, 07. 2017. [ bib | DOI ] |
| [2] | Matan Atzmon, Haggai Maron, and Yaron Lipman. Point convolutional neural networks by extension operators, 2018. [ bib | arXiv ] |
| [3] | Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks, 2013. [ bib | arXiv ] |
| [4] | Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 25, pages 1097--1105. Curran Associates, Inc., 2012. [ bib | .pdf ] |
| [5] | Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions, 2014. [ bib | arXiv ] |
| [6] | Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. [ bib | arXiv ] |
| [7] | Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation, 2014. [ bib | arXiv ] |
| [8] | Hyeonwoo Noh, Seunghoon Hong, and Bohyung Han. Learning deconvolution network for semantic segmentation, 2015. [ bib | arXiv ] |
| [9] | Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: convolutional networks for biomedical image segmentation. volume 9351, pages 234--241, 10. 2015. [ bib | DOI ] |
| [10] | Pierre Biasutti, Vincent Lepetit, Jean-François Aujol, Mathieu Brédif, and Aurélie Bugeau. Lu-net: An efficient network for 3d lidar point cloud semantic segmentation based on end-to-end-learned 3d features and u-net, 2019. [ bib | arXiv ] |
| [11] | Mohammad Havaei, Axel Davy, David Warde-Farley, Antoine Biard, Aaron Courville, Yoshua Bengio, Chris Pal, Pierre-Marc Jodoin, and Hugo Larochelle. Brain tumor segmentation with deep neural networks. Medical Image Analysis, 35:18–31, Jan 2017. [ bib | DOI | http ] |
| [12] | Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection, 2016. [ bib | arXiv ] |
| [13] | Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection, 2018. [ bib | arXiv ] |
| [14] | C. Lawrence Zitnick and Piotr Dollár. Edge boxes: Locating object proposals from edges. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors, Computer Vision -- ECCV 2014, pages 391--405, Cham, 2014. Springer International Publishing. [ bib ] |
| [15] | Seyyed Hossein Hasanpour, Mohammad Rouhani, Mohsen Fayyaz, and Mohammad Sabokrou. Lets keep it simple, using simple architectures to outperform deeper and more complex architectures, 2018. [ bib | arXiv ] |
| [16] | T. Zebin, P. J. Scully, N. Peek, A. J. Casson, and K. B. Ozanyan. Design and implementation of a convolutional neural network on an edge computing smartphone for human activity recognition. IEEE Access, 7:133509--133520, 2019. [ bib | DOI ] |
| [17] | Cody A. Coleman, D. Narayanan, Daniel Kang, T. Zhao, Jian Zhang, L. Nardi, Peter Bailis, K. Olukotun, C. Ré, and M. Zaharia. Dawnbench : An end-to-end deep learning benchmark and competition. 2017. [ bib ] |
| [18] | Andrew Ng. CS229 lecture notes - supervised learning. https://see.stanford.edu/Course/CS229, 2012. [ bib ] |
| [19] | Amelie Byun. CS231n lecture notes - convolutional neural networks for visual recognition. https://cs231n.github.io/, 2017. [ bib ] |
| [20] | Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org. [ bib ] |
| [21] | Aurlien Gron. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. O’Reilly Media, Inc., 1st edition, 2017. [ bib ] |
| [22] | François Chollet. Deep Learning with Python. Manning, November 2017. [ bib ] |
(počet zobrazení stránky: 2694)